AeroMind CS 175: Project in AI
Progress report
Project Summary
Our project focuses on stabilizing a quadrotor using Reinforcement Learning with PPO (Proximal Policy Optimization). We integrate PyDrake and PyFlyt for simulation, utilizing Stable-Baselines3 for training. The goal is to train an RL agent to control the quadrotor efficently while incorporating traditional control methods like LQR for stability before PPO takes over. We aim to enhance performance through hyperparameter tuning, vectorized environments, and robust evaluation.
Approach
The system follows a structured RL pipeline:
1 - Environment setup
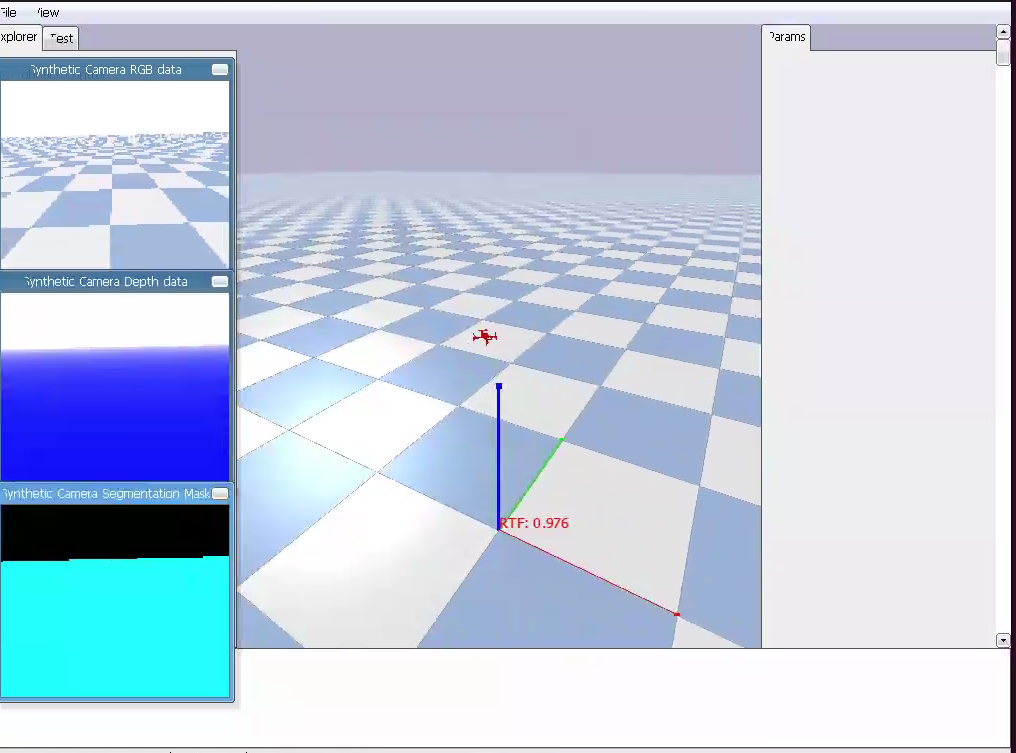
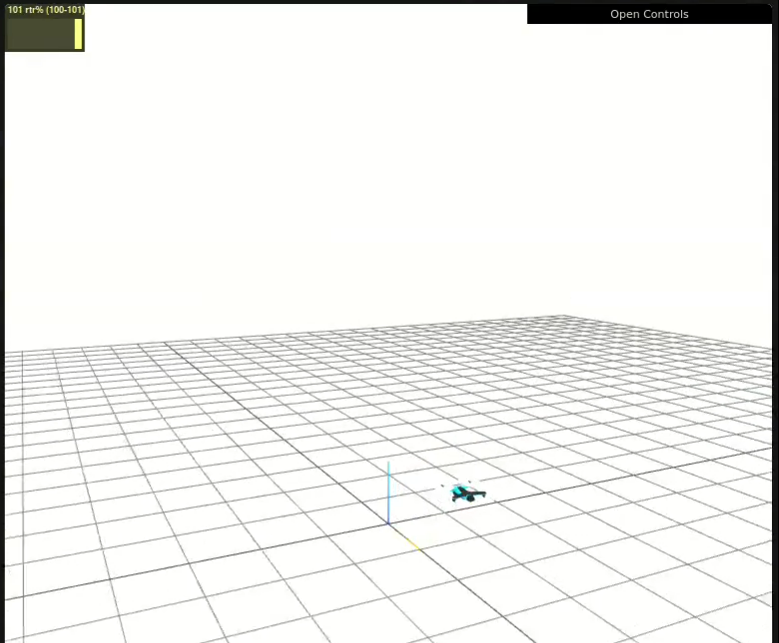
- Quadrotor simulation environments using pyflyt amd pydrake
- Observation space: position, velocity, angular velocity
- Action space: motor thrusts
- Reward function: balancing stability, energy efficiency, and goal tracking
2 - Control algorithms
- PPO
- Implemented using stable-baselines3
- Trains a policy to stabilize the quadrotor
- LQR
- Acts as a baseline for performance comparison
- Provides a stable reference trajectory for PPO
3 - Enchancements Implemented
- Code refactoring
- Extracted common functions into utils.py for better modularity
- shifted hyperparameters to config.yaml for easier tuning
- Training improvements
- Vectorized environments to accelerate learning
- Checkpointing every 100,000 steps
- Exception handling to improve robustness.
- Hyperparameter optimization
- Integrated optuna for automatic tuning of learning rates, gamma, etc.
Evaluation
We evaluate our approach using both qualitative and quantitative metrics:
Quantitative Metrics
- Reward progression: tracks training stability and policy improvement
- Trajectory tracking: measures deviation from a reference trajectory
- Energy consumption: evaluates power efficiency in control
Qualitative
- Visualization with meshcat: real-time simulation of quadrotor behavior
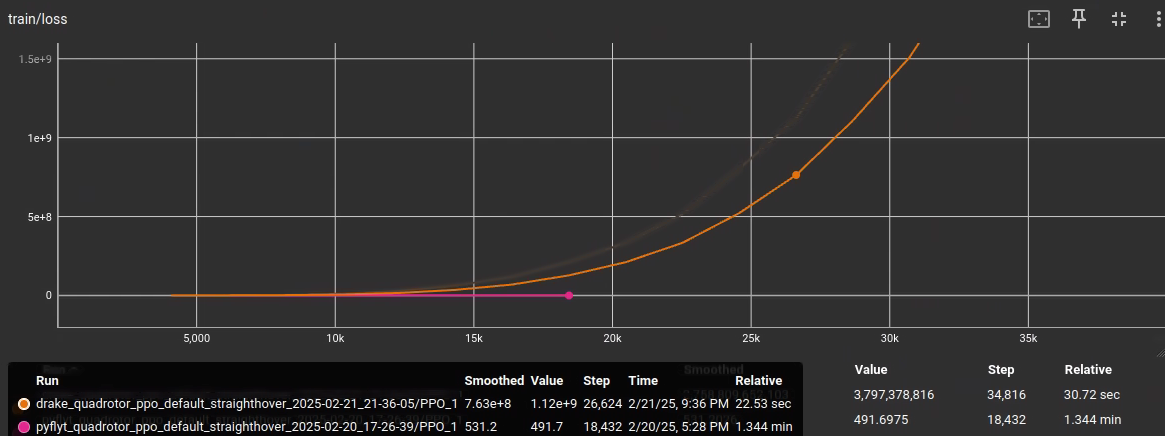
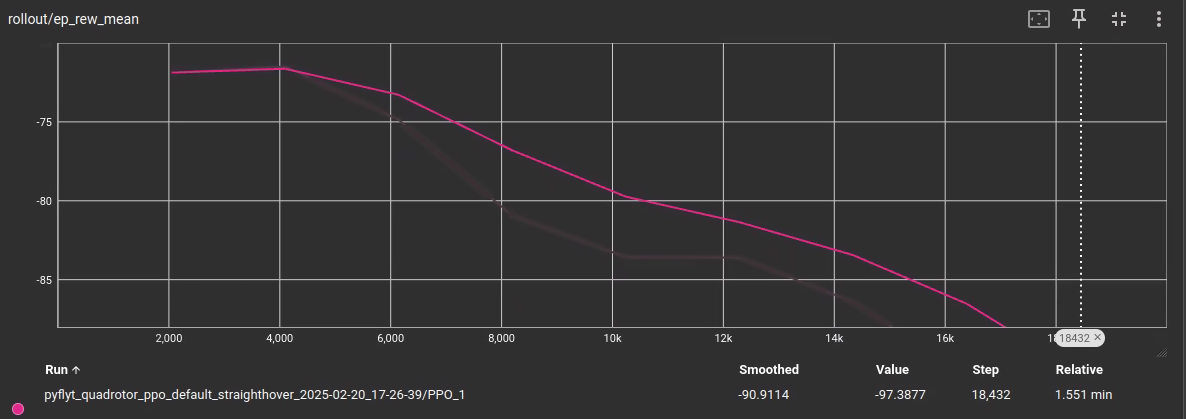
- TensorBoard logging: monitors reward trends, loss curves, and policy updates
- Failure mode analysis: identifies scenarios where RL fails to stabilize the drone
Current Results
- PPO has shown promising stabilization but struggles with precise hovering.
- LQR provides better immediate stability but lacks adaptability
- Tuning is in progress to improve PPO convergence
- pydrake seems to run faster but results are less promising so far. Our LQR controller is functioning and uses meshcat for visualization
- pyflyt runs slower, but the results are more promising so far, (the training loss at least decreases). It also allows us to save the renderings as RGB arrays, similar to the environments from exercise 2
Remaining Goals and Challenges
Next steps
- Improve PPO performance
- Further refine the reward function
- Experiment with different network architectures
- Compare PPO and LQR hybrid approaches
- Investigate if LQR can guie PPO training
- Try using LQR to generate a curriculum for RL training
- Robust testing
- Introduce wind disturbances and sensor noise
- Test in more challenging scenarios
Challenges
- Training stability: PPO can still diverge in some cases.
- Computation costs: vectorized environments help but require more tuning.
- Generalization: ensuring the policy works across different conditions
Resources Used
- Stable-baselines3: PPO implementation
- PyFlyt and PyDrake: Quadrotor simulation and control
- Optuna: Hyperparameter tuning
- Tensorboard: Training visualization
- Github and Stackoverflow: Documentation and troubleshooting